读取存在的文件,要用到docx库中的Document
document = Document(file_path),file_path表示要打开的Word路径,没有参数表示新建文档。
代码:
from docx import Document
document = Document('test.docx')
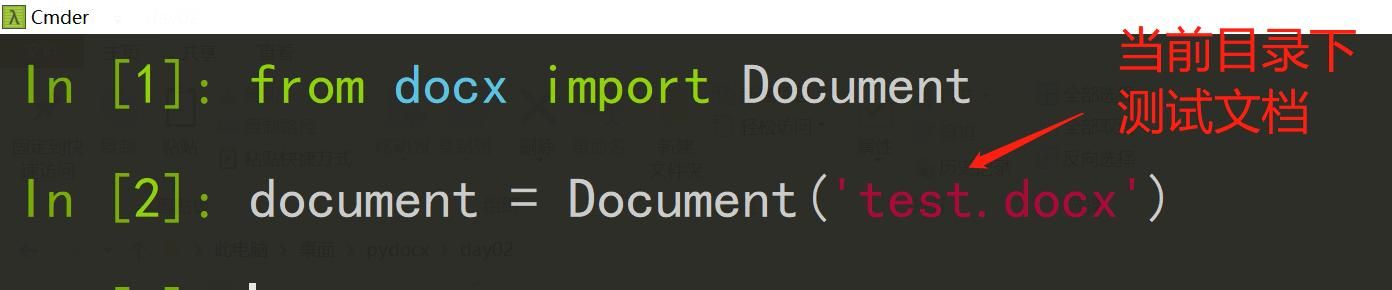
docx打开文件
获取段落paragraph一个document文档包括一个或者多个段落,都在document的paragras属性中,document.paragraphs返回所有段落对象的列表。
例如paragrahps = document.paragraphs
paragraphs[0] --> 表示第1段对象
paragraphs[1] --> 表示第2段对象
……
len(pargraphs) --> 查看文档有多少个自然段
代码:
paragraphs = document.paragraphs # paragraphs表示得到的所有段落列表
type(paragraphs) # 返回列表
p1 = paragraphs[0] # p1表示第一段段落对象
len(paragraphs) # 检查文档一共有多少段
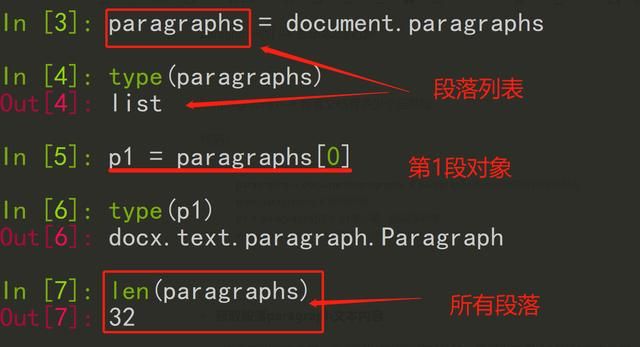
段落对象
获取段落paragraph文本内容.text用于获取文本内容,不仅可以获取段落对象的,还可以获取块对象的文本内容
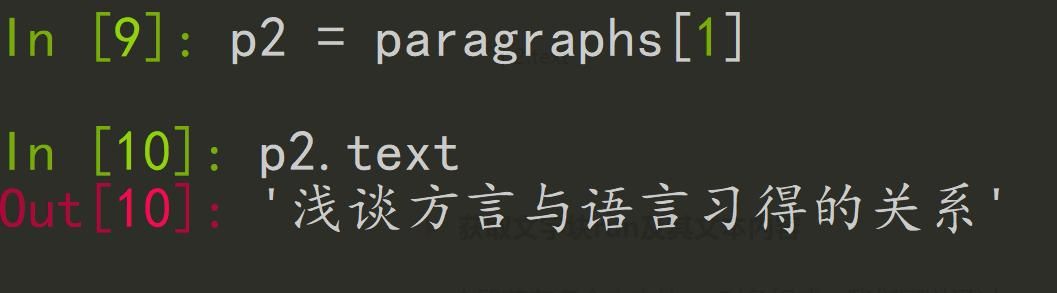
代码:以p2第二段对象为例
p2.text
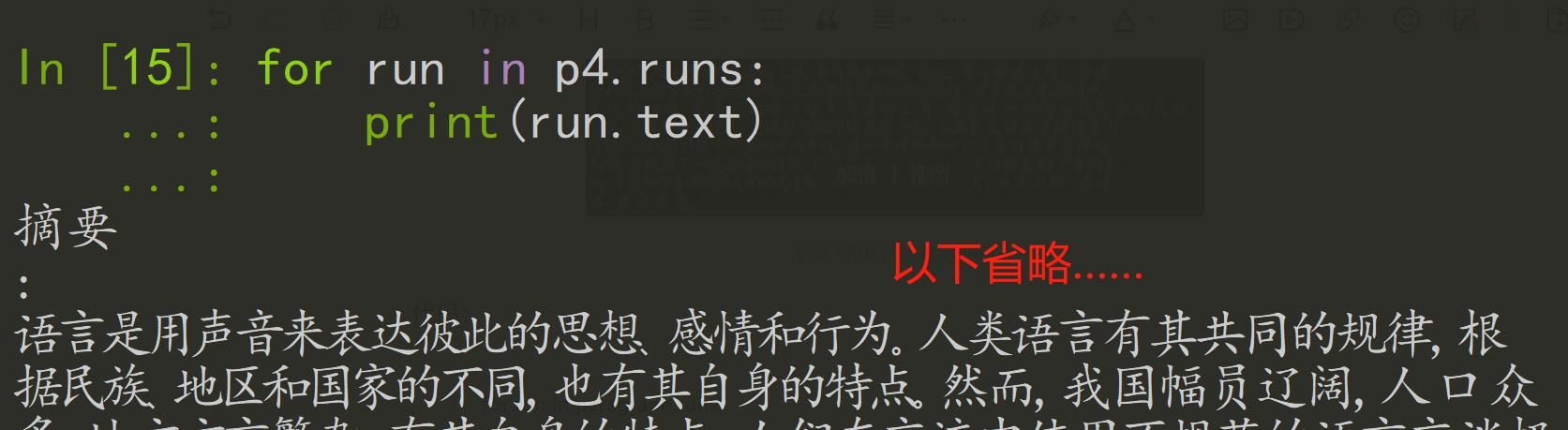
一个段落有多个文本块run对象组成,我们可以通过paragraph.runs获取所有块对象,然后通过.text获取其内容,这里以第4段为例p4 = paragraphs[3]

代码:
for run in p4.runs:
print(run.text)
代码:
for paragraph in document.paragraphs:
for run in paragraph.runs:
print(run.text)
和openpyxl 操作excel类似,table表格遍历采取三级循环样式
A:按照行遍历
for table in document.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
B: 按照列遍历
for table in document.tables:
for column in table.columns:
for cell in column.cells:
print(cell.text)
概况一下:要获得文本,都可以使用.text,不管是段落paragraph,还是run,或者是table表格的cell单元格。
,